NLP & Maslow's Human Needs Theory
An attempt to understand the motivations behind misleading content on social media.

Kaveesh Khattar
Jun 30, 2023


What is disinformation?
Disinformation—false or misleading information spread intentionally—competes with accurate information, clouding judgment and eroding trust. It infiltrates social media platforms, mimicking credible sources, much like weeds can appear deceptively similar to flowers, making it challenging to distinguish truth from falsehood.
In recent times, during the devastating wildfires in Los Angeles, prominent figures like President-elect Donald Trump and Elon Musk disseminated false information via social media. Trump incorrectly attributed the firefighting challenges to California Governor Gavin Newsom's water policies, while Musk misleadingly linked the fires to the fire chief's focus on diversity initiatives. These unfounded claims diverted attention from the actual causes and hindered effective response efforts. [The Verge, Jan 2025]
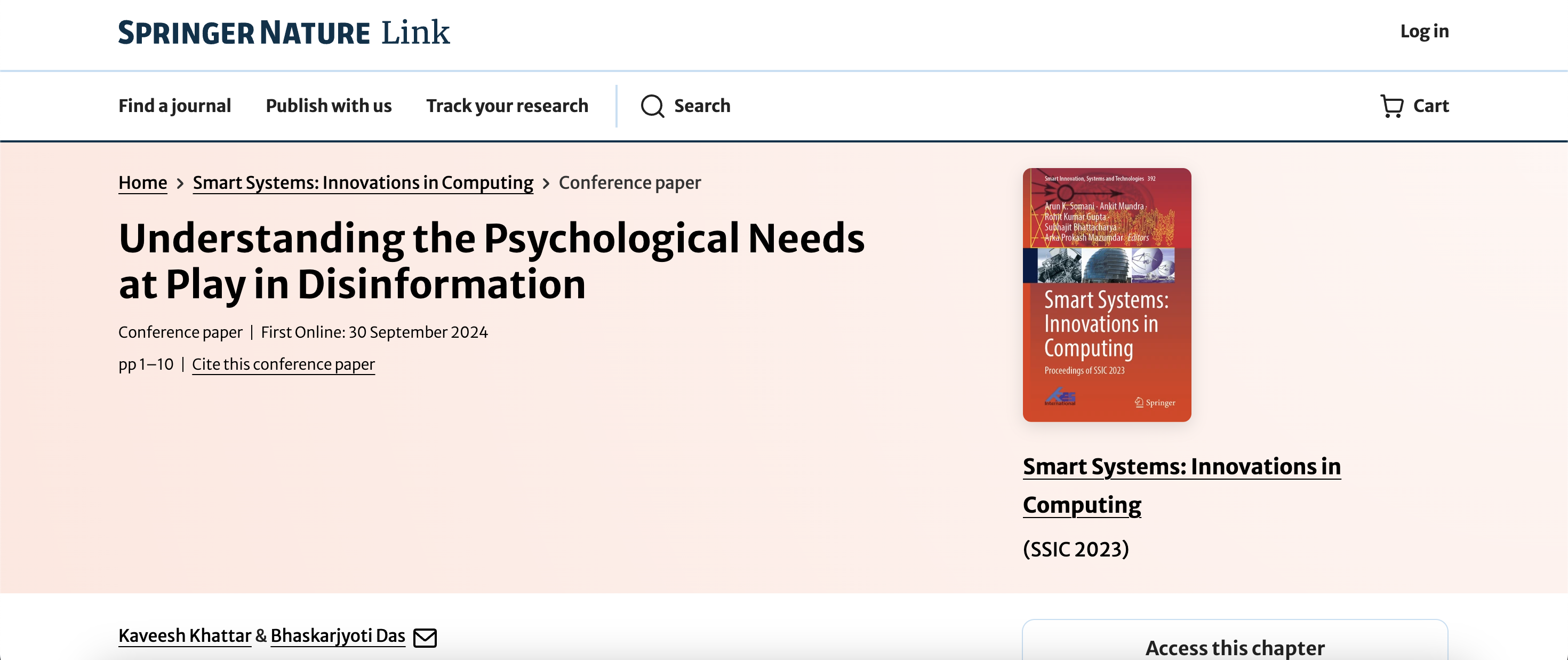
How can Maslow help?
The connection between psychological factors and disinformation is supported by extensive research linking language use to psychological states and behaviors. Tools like Linguistic Inquiry and Word Count (LIWC) have demonstrated their utility in uncovering psychological insights across domains, including mental health, crisis prevention, and substance abuse intervention.
In disinformation research, limited but significant work, such as analyzing rumors and fake news spreaders, has leveraged psycholinguistic features like emotions, readability, and personality traits.
While this approach remains underexplored in disinformation, prior applications of Human Needs Theory (HNT) in understanding human needs during crises highlight its potential relevance in this context.

The Problem Statement
An exploration of the psychological and emotional processes underlying to improve understanding of the motivations and patterns driving the production of disinformation.
Technology
The technology we adopted revolved around Python for the main reason that a lot of machine learning packages are written in Python and it has a lot of community support in this domain.
We started with with what we needed, not jumping straight to the big libraries. I started working with TFIDF Vectorisation and understanding the math behind it. Then I implemented TFIDF with Linear Regression to make things more clear. After this, I went to work on combining TFIDF with Naive Bayes, SVM and XGBoost. At this point, I was working with more straight-forward, smaller text.
Now, let's move to the actual dataset.

Dataset
The dataset is multi-label in nature though the labels are not hierarchical. The dataset is small consisting of only 5067 labeled samples and is imbalanced (not having an equal number of labels in each of the 5 layers described above). It is hard to do any supervised machine learning with such a small imbalanced dataset. Hence, suitable data augmentation strategies have been adopted to make a balanced dataset. I'll talk more on this soon.
The original imbalanced dataset of 5067 samples is transformed into a balanced dataset of 34,829 samples. The average word count of the balanced dataset (used for training) was around 17.
This inspired us to create a student-driven question bank, where students could submit questions to help others prepare more effectively. Additionally, the platform would generate daily quizzes from these questions, reducing teachers' workload and streamlining the preparation process.
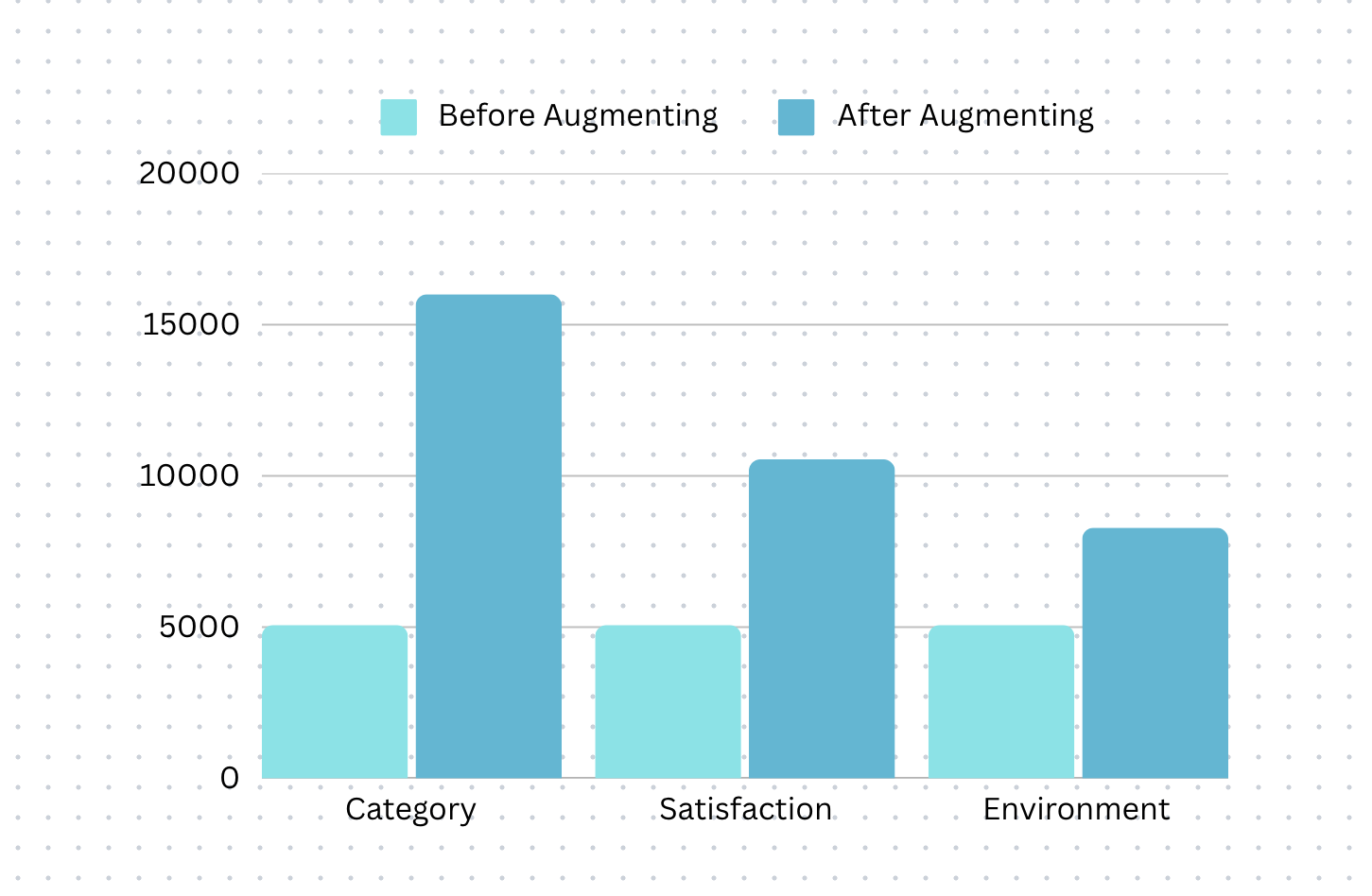
Balancing the dataset
Now in the bar chart above it might look like the dataset is not balanced at all but that's not the case at all. In fact, a significant time was spent in balancing the dataset.
So, each label above has three sub-categories, and the sub-category with the maximum value was taken as the number of new instances to be reproduced, so internally under each label, all sub-categories have the same number of rows.
Machine Learning (TFIDF with Naive Bayes, SVM & XGBoost)
Two traditional machine learning algorithms i.e. Naive Bayes (NB) and Support Vector Machines (SVM) along with an ensemble learning algorithm i.e. XGBoost, were chosen as baseline estimators to evaluate the performance of the models.
For feature extraction, both statistical approaches such as Term Frequency-Inverse Document Frequency (TFIDF), and distributional semantics-based methods such as Facebook's FastText are used. FastText is preferred to Word2Vec due to its capability to handle out-of-vocabulary words and character n-gram-based approach.
Deep Learning (spaCy, kTrain)
For the deep learning-based model, two approaches have been used. A lightweight Python library (Ktrain) that uses DistilBERT (distilbert-base-uncased) and built on top of TensorFlow and Keras, was utilized. The spaCy library with Hugging Face Transformer model that uses 'bert-base-cased' has been the alternative pursued for the deep learning approach.
Metrics & Discussion
For the deep learning models, Cohen's Kappa Score and Matthews Correlation Coefficient have been calculated. Since traditional accuracy metrics are sensitive to class imbalance, Matthews Correlation Coefficient offers a better approach essentially measuring the correlation between true and predicted value.
Cohen's Kappa Score measures the agreement between two raters, in this case, the predicted labels and the true labels.
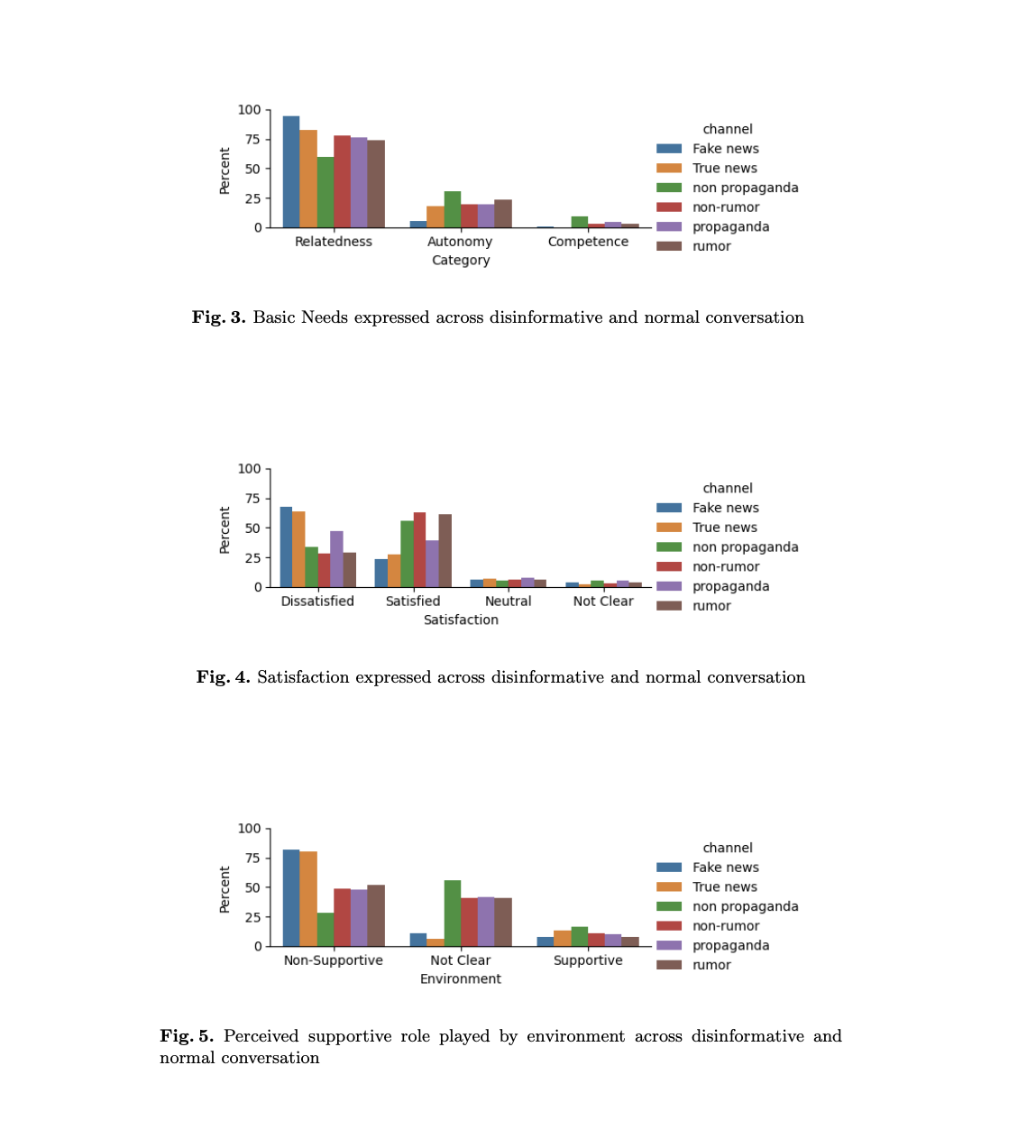
Fake News show the least satisfaction and maximum dissatisfaction. Non-rumour shows maximum satisfaction being plain fact-based news. Rumour is caused by anxiety to address the need for information. So, as compared to non-rumor, it shows less satisfaction but satisfaction is still at a higher level than that of fake news.
A similar conclusion can be derived from propaganda and non-propaganda. Among the basic needs, relatedness is the main reason driving people on social media, followed by a need for autonomy. Competence is not such a pressing need. It is also clear that most people go to social media to vent about the lack of support from the environment towards their basic needs.
The Final Result
We submitted our paper to Springer SSIC for publication, and I had the opportunity to present it and our paper was successfully published!