Lights, Camera, AI
Creating unique representations of real world entities using diffusion based GANs.

Kaveesh Khattar
Oct 20, 2024

The Problem Statement
Generative Adversarial Networks (GANs), particularly Deep Fusion GANs (DF GANs), have demonstrated effectiveness in generating realistic images.
However, challenges remain in enabling the creation of unique, contextually accurate representations of objects, when guided by labelled inputs and script-based prompts.
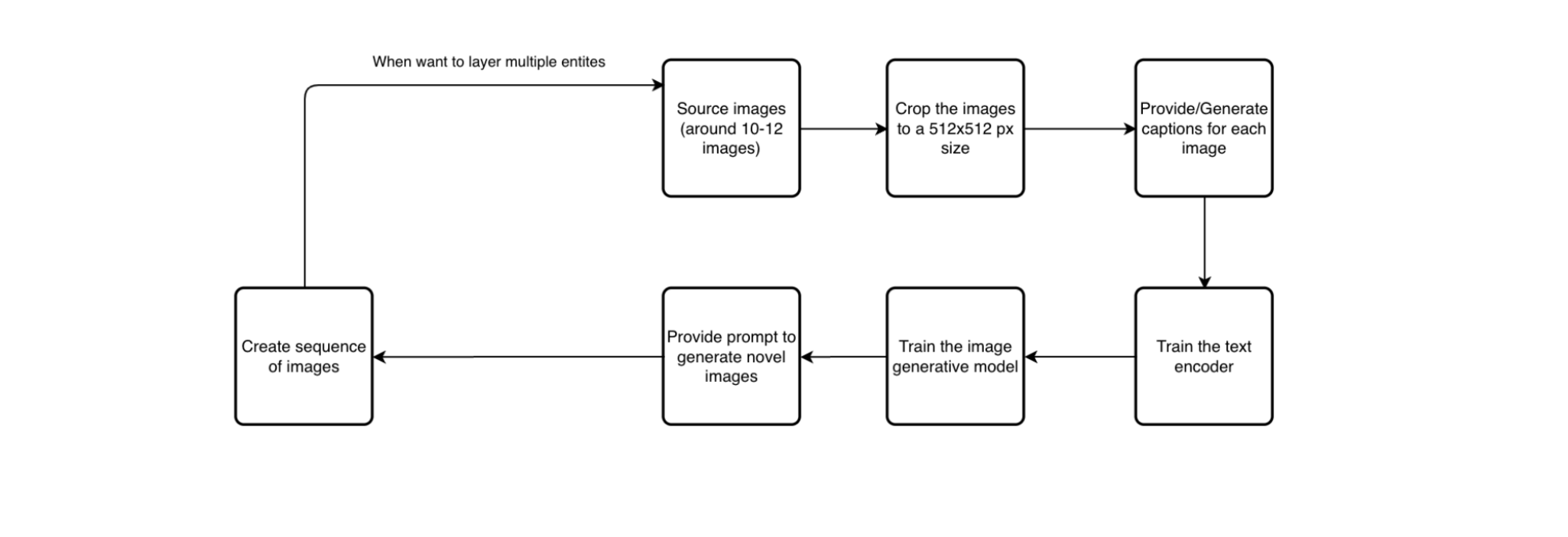
Our Idea and Proposal
1. Sourcing Images and performing transformation
We curated a diverse dataset of high-resolution photographs featuring humans in various activities and objects across categories, preprocessing them to ensure compatibility with the pretrained DF-GAN.
Images were resized to 512x512 pixels, normalized, and annotated with context-relevant labels and tokens to guide the model in generating coherent, context-aware outputs.
2. Train text encoder
The key phase in training the model involves interpreting and using the provided labels, tokens, and textual prompts for scene generation. The text encoder must transform textual inputs into a format that can be combined with the image data to guide the model effectively.
Through iterative training, the text encoder refines its ability to extract relevant context from the input, enabling the model to understand the intended instructions. This results in a synergy between textual and visual modalities, ensuring the generated outputs are both contextually relevant and visually appealing.
3. Train image encoder
Training the image encoder follows the text encoder, where the model learns to extract visual features from pre-processed images. This phase ensures that the encoder identifies key details and patterns needed for the model to recognize the subject of the image.
By optimizing the image encoder alongside other DF-GAN components, the model learns to bind visual and textual information. The collaborative training between the image and text encoders ensures that the model generates coherent and contextually accurate representations.
4. Prompt and epoch configurations for optimum outputs
Optimizing image generation requires careful selection of text prompts and epoch configurations to guide the model in producing desired visual outcomes. Through iterative testing and adjustments, these parameters ensure high-quality, contextually relevant images that meet specific creative goals.
5. Scene generation for prompts with multiple sentences
Setting up multi-sentence prompts enables the model to generate coherent, context-rich narratives by guiding scene creation with sequential descriptions. This approach ensures the production of consistent, dynamic visuals that reflect the intended storyline or scenario.
The Final Result
Experimental results show that the pre-trained DF-GAN effectively generates diverse, realistic object representations and extrapolates from unseen data using labeled photographs and distinguishing tokens. Additionally, the model successfully creates logically consistent scenarios based on short, script-based prompts.

We submitted our paper to Springer Series: Lecture Notes in Networks and Systems, for publication, and our paper was successfully published!